Les algorithmes pour les paris sportifs : comment ca marche ?
Quel est le point commun entre une banque, un super-ordinateur et la Coupe du Monde de football ? Réponse : un algorithme prédictif !
Comme les animaux aux super-pouvoirs de divination tel Paul le Poulpe, ils ressortent comme des escargots à l’approche du Mondial de foot. Leur objectif : fournir les pronostics football les plus précis et les plus fiables possibles.
A l’instar des parieurs et autres traders pour des bookmakers, les algorithmes analysent les matchs passés et les forces en présence pour établir le pronostic d’un match de football. Leur postulat : le passé est aussi important que le futur.
Comme vous allez le constater, les données ont révolutionné à la fois le football, son économie ainsi que le business des paris sportifs.
Quand les données ont révolutionné le football…
Les data ont révolutionné le monde du football ! De nos jours, entre les joueurs portant des chasubles avec GPS embarqué, les caméras qui analysent les actions des joueurs en temps réel et les cellules de recrutement hyper-connectées aux bases de données, les données sont partout..

Les enjeux économiques et sportifs sont tels que l’analyse des données est devenue un vecteur d’avantage concurrentiel sur les autres équipes. Deux anecdotes désormais célèbres dans le monde du “football analytics” illustrent le poids de l’analyse des données.
La première retrace l’histoire du titre de champion d’Angleterre acquis en 2012 par Manchester City et son coach italien, Roberto Mancini. Cette saison là, après avoir passé au crible des milliers de statistiques dont les 400 corners tirés sur les saisons précédentes, les 11 analystes des Citizens concluent que les corners les plus dangereux sont les corners rentrants, un secteur où City n’excelle pas. Mancini lui exigeait des corners sortants. Par la suite, Manchester City inscrira 15 buts sur corners.
L’autre anecdote célèbre se passe à Arsenal en 2004. Pour remplacer un Patrick Vieira sur le départ, Arsène Wenger analyse les statistiques des joueurs de tous les ligues européennes pour trouver un milieu de terrain capable de courir 14 kilomètre par rencontre. Il déniche alors un joueur inconnu du grand public qui est en train d’éclore à l’OM : Mathieu Flamini.
Certaines sociétés ont très vite exploité cette nouvelle mine d’or et ont constitué au fil des années des bases de données sur les compétitions, les équipes et les joueurs qui valent des fortunes. Elles sont une petite poignée à fournir aujourd’hui bookmakers, médias et clubs professionnels en base de donnée et outils d’aide à la décision statistiques. Les deux plus importantes dans le monde sont Sportradar et Stats Perform (ex-Opta).
Algorithmes, banques et Coupe du Monde
La banque internationale Goldman Sachs a mobilisé son équipe de recherche macro-économique lors des 3 dernières Coupe du Monde pour pondre une prédiction algorithmique du vainqueur. Si le puissant algo a fait choux blanc à chaque fois (donnant à chaque fois le Brésil), l’approche retenue est très intéressante pour comprendre comment fonctionne un algorithme de prédiction :
Nous avons récolté des données sur les caractéristiques de l’équipe, les joueurs et les dernières performances des équipes et les avons passé à la moulinette de 4 modèles de machine learning pour analyser le nombre de buts inscrits à chaque match. Le modèle a ensuite appris la relation entre ces caractéristiques et les buts inscrits, en utilisant les scores de tous les matchs de Coupe du Monde et de Coupe d’Europe depuis 2005…
A ce jeu, ce sont les banques ING et Nomura qui sont arrivées le plus proche du résultat final avec comme prédiction une finale entre la France et l’Espagne.
Pour revenir sur l’algorithme de la Goldman Sachs, il a tout de même réussi à trouver 13 des 16 équipes en 1/8e de finale avec un taux de réussite de 68%.
Comment ca marche un algorithme prédictif ?
Alors pour fabriquer un algorithme prédictif il vous faut : un bon ordinateur, de bonnes grosses data toutes fraîches et un modèle mathématique. Bon ok, c’est un peu trop simpliste comme vision. Mais dans les faits, les deux composantes essentielles d’un bon algorithme prédictif sont les données et le/les modèles appliqués.
Le nombre de buts marqués et encaissés, la possession de balle, le nombre de tirs cadrés, de passes réussies, de corners, les zones de jeu…tous les faits de jeu sont quantifiables dans un match. Mais peut-on établir des tendances à partir de l’observation de ces critères ? N’en déplaise aux défenseurs de la glorieuse incertitude du sport, la réponse est oui.
Dans le livre “The number games : why everything you know about football is wrong”, David Sally et Chris Anderson, tentent de démystifier plusieurs idées préconçues sur le football grâce à l’analyse des statistiques. A commencer par l’importance des corners :
Le nombre total de buts que marque une équipe n’augmente pas avec le nombre de corners qu’elle gagne. La corrélation est fondamentalement de zéro. Vous pouvez avoir un corner ou 17 corners: cela n’aura pas d’impact significatif sur le nombre de buts que vous marquez.
Mais quel critère a le plus de poids dans la probabilité de victoire d’une équipe ? Ces derniers se penchent naturellement sur ce qu’il y a de plus rare dans le football : les buts.
Sally et Anderson ont donc utilisé la loi de probabilité préférée des bookmakers, la loi de Poisson, pour prédire la distribution du nombre de buts par match par des équipes du Big 5 entre 1993 et 2011 (nombre de matchs sans but, avec un but…). Comme vous pouvez le voir dans le graph ci-dessous, l’écart entre la réalité et leurs prédictions est très mince.Etude sur la distribution du nombre de buts par match en Europe par Sally et Anderson (source : ecofoot.fr)
La loi de Poisson ou comment prédire le score d’un match
Vous allez découvrir comment bookmakers et robots pronostic foot arrivent à prédire le score d’un match de football et in fine, le résultat le plus probable.
Sur son blog, le bookmaker international Pinnacle.com, explique de manière détaillée comment à partir d’un échantillon de matchs conséquents ( à minima une saison), un bookmaker arriver à calculer un score probable et convertir les probabilités estimées en cotes.
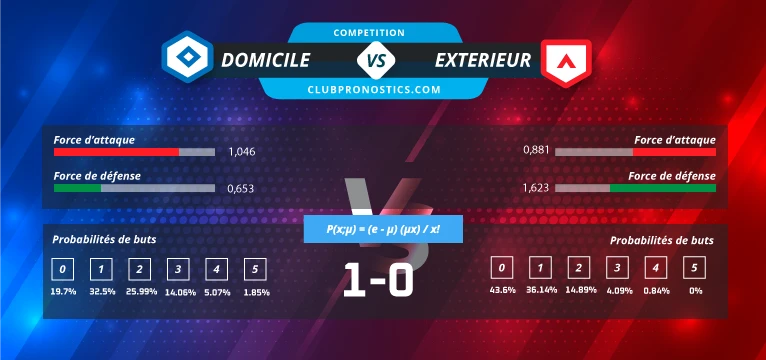
- Calculer la force d’attaque : soit le rapport entre la moyenne de buts inscrits par l’équipe et celle de la compétition
- Calculer la force de défense : soit le rapport entre la moyenne de buts encaissés par l’équipe et celle de la compétition
- Prédire le nombre de buts marqués par l’équipe domicile et extérieur : il s’agit ici pour chaque équipe, de multiplier la force d’attaque de l’équipe par le potentiel défensif de l’adversaire et par le nombre de buts inscrits à domicile pour l’équipe domicile, à l’extérieur pour le visiteur.
- Utiliser la loi de Poisson pour estimer la probabilité du nombre de buts marqués par chaque équipe : la formule va permettre à partir des différents types d’événements (nombre de buts de 0 à 6) et du nombre de buts probable inscrit par chaque équipe, d’obtenir la probabilité de chaque occurrence. Par exemple, le chance que l’équipe extérieur marque 1 but et l’équipe domicile 2 buts.
- Déduire le score attendu : en sortant les probabilités les plus fortes de chaque événement, on obtient alors le score attendu.
Naturellement, si la loi de Poisson fait ressortir une certaine logique dans le caractère aléatoire des buts, elle est loin d’être parfaite. Un modèle plus évolué prendrait en compte par exemple le degré d’importance du match pour les deux équipes, l’absence d’un des joueurs clés ou encore l’arrivée d’un nouvel entraîneur.
L’algorithme idéal serait un algorithme intelligent qui apprend de ces erreurs et qui aurait accès à des centaines de paramètres pour en fin de compter, mesurer le poids de chacun de ces facteurs sur l’issue d’un match et s’adapter en conséquence.
Le modèle de Dixon-Coles : une amélioration de la loi de Poisson
D’après les matheux, la loi de Poisson présente deux inconvénients majeurs : elle sous-estime les petits scores (0-0, 1-0,1-1) et donne autant d’importance aux événements anciens qu’aux récents. Le modèle de Dixon-Coles vient corriger ces points. L’algorithme prédictif Betegy utilise d’ailleurs une version modifiée de ce modèle en intégrant la dynamique des deux équipes.
En bref
Si la loi de Poisson et ses déclinaisons sont au cœur de la plupart des algorithmes prédictifs, ces derniers ne se résument pas à ces seuls modèles mathématiques. Leur conception est bien plus complexe qu’il n’y paraît. A ce propos, Paul Sada, le fondateur du robot pronostic foot le plus en vue actuellement, a partagé avec nous le secret de son « Algo de Paulo » :
Lors de la conception de l’algorithme où à chaque optimisation, nous étudions indépendamment des centaines de paramètres pour lesquels nous récupérons les données sur les saisons passées et l’actuelle. Une fois cette phase d’étude faite, nous associons les paramètres entre eux en ajoutant une pondération différente à chacun d’entre eux pour que la complémentarité soit optimale : c’est cette phase qui est la plus complexe. Tu t’en doutes bien, les paramètres les plus impactants et donc possédants la pondération la plus élevée sont ceux qui sont directement liés au nombre de buts marqués/concédés.
Mais assez parlé de formules mathématiques barbares et revenons-en au terrain. Le vrai avantage des modèles mathématiques appliqués aux pronostics footballistiques c’est qu’ils permettent de voir instantanément les forces en présence, sans avoir la moindre connaissance de l’historique championnat et des équipes.
Si par exemple, vous souhaitiez vous mettre à parier sur un championnat exotique comme le championnat biélorusse, un petit tour par un algo s’impose.Ce dernier présente surtout un avantage indéniable par rapport à un humain : il est dépourvu de tout affect et n’a aucune équipe de coeur lui !